基本概念
Rime 是一个输入法框架,并不是狭义上的“输入法”,而是将各种输入法的共性抽象出来的算法框架。通过不同的配置文件,Rime 可以支持多种输入方案(Schema),这个所谓的输入方案就是我们狭义上的“输入法”。比如朙月拼音输入法就是 Rime 自带的一种输入方案,另外还有比如四叶草输入法(https://github.com/fkxxyz/rime-cloverpinyin)等等。
鼠须管、小狼毫、中州韵分别是 Rime 在不同操作系统下的实现程序。
Rime 的配置、词库文件均使用文本方式,便于修改。所有文件均要求以 UTF-8 编码。
在配置文件中,以 # 号开头表示注释。
配置文件所在的目录
Rime 有两个重要的配置目录:
共享配置目录
- 【中州韻】
/usr/share/rime-data/ - 【小狼毫】
"安裝目錄\data" - 【鼠鬚管】
"/Library/Input Methods/Squirrel.app/Contents/SharedSupport/"
PS:其实应该叫做”程序配置目录”
用户配置目录
- 【中州韻】
~/.config/ibus/rime/(0.9.1 以下版本爲~/.ibus/rime/) - 【小狼毫】
%APPDATA%\Rime - 【鼠鬚管】
~/Library/Rime/
共享目录下放置的是 Rime 的预设配置,在软件版本更新时候,也会自动更新该目录下的文件。所以请不要修改该目录下的文件。
用户目录则放置用户自定义的配置文件。我们要做的修改都放在用户目录下。
对于鼠须管而言,用户目录初始时只有如下几个文件。
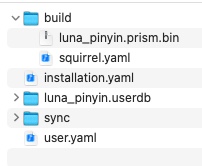
installion.yaml 文件记录的是当前 Rime 程序的版本信息。其中有一个字段 installation_id 用来在同步用户词典时唯一标记当前 Rime 程序。
user.yaml 文件记录用户的使用状态。比如上次“重新部署”的时间戳,上次选择的输入方案等。
build 目录下放的是每次“重新部署”后生成的文件。包括字典文件编译后生成的「.bin」文件,包括与自定义配置合并后生成的各种 yaml 配置文件。
xxx.userdb 目录下放的是对应输入方案的用户词典。即用户在使用时候选择的词组、词频等动态信息,这个目录是实时更新的。
sync 目录是用来做用户数据同步的。每个 sync/installation_id 目录对应不同电脑上的 Rime 程序的用户数据。(如果你由多台电脑安装了 Rime,并设置了同步。)按照作者的说法,Rime 的用户词典同步原理是:
手工从其他电脑复制或者从网盘自动同步 ⇒ sync/*/*.userdb.txt ⇒ 合并到本地 *.userdb ⇒ 导出到 sync/<installation_id>/*.userdb.txt。
关于调试
Rime 的日志目录放在如下为止:
- 【中州韻】
/tmp/rime.ibus.* - 【小狼毫】
%TEMP%\rime.weasel.* - 【鼠鬚管】
$TMPDIR/rime.squirrel.* - 早期版本
用户配置目录/rime.log
PS:我的鼠须管刚安装好后,目录文件一直是空的。即使故意写错配置文件,也没有输出日志。直到我在 macOS 的活动监视器中强制退出鼠须管进程,并重启鼠须管之后,才正式输出日志。=。=
修改配置
如果想要修改配置,请不要直接修改原有的 xxx.yaml 文件,而是应该新建一份 xxx.custom.yaml 文件,其中 xxx 与原文件名相同。
修改方案定义文件时需要命名为 schema_id.custom.yaml ,而不用再加 schema 写成 schema_id.schema.custom.yaml
在 .custom.yaml 文件中对于要修改的配置项,都需要放在 patch 根节点下面。
每次修改配置,都需要在鼠须管的菜单中选择“重新部署”后才能生效。
修改候选词个数
Rime 默认每次出现的候选词个数为 5 个,我们可以将其修改为 1~9 之间的任意数。
在用户目录下新建一个 default.custom.yaml 文件(default.yaml 文件可以在共享配置目录下找到),写入如下内容:
patch: "menu/page_size": 9 # 字段名加不加双引号都可以
或者是這樣:
patch:
menu:
page_size: 8
# 但是注意这种写法是覆盖整个 menu 字段。好在默认情况下,menu 下一级也只有 page_size 字段,如果是有多个下级字段,请不要这么写。
然后在菜单中选择“重新部署”,以将新配置生效。
上诉的 default 文件是修改所有输入方案的候选词个数,如果只想针对某个输入方案做调整,比如对于朙月输入方案,那么只需要在用户目录下建立 luna_pinyin.custom.yaml 文件并写入如上内容,再重新部署即可。(注意,对输入方案定义文件 xxx.schema.yaml 的修改,新建的文件名只需要是 xxx.custom.yaml,并不需要加上 schema,写成 xxx.schema.custom.yaml 这样。)
修改方案选单
鼠须管默认使用组合键 ctrl + ![]() 或者
或者 F4 键来唤出方案选单。

在唤出的方案选单列表中:
1 表示当前在用的输入方案。
2 表示当前输入方案的状态。包括 中文/英文,半角/全角,简体汉字/繁體漢字,中文句逗/英文句逗。(输入方案的可切换状态,请参考后续的 switches 章节)
3 及后续选项表示其他可选的输入方案。
我们可以在共享配置目录的 default.yaml 中找到方案选单的定义:
schema_list: - schema: luna_pinyin # 朙月拼音 - schema: luna_pinyin_simp # 朙月拼音-简体 - schema: luna_pinyin_fluency # 朙月拼音-语句流 - schema: bopomofo # 注音输入法 - schema: bopomofo_tw # 注音输入法-台湾繁体 - schema: cangjie5 # 仓颉五代输入法 - schema: stroke # 五笔画输入法(非五笔输入法,而是用hspnz五个键代表横竖撇捺折。是繁体的笔画编码哦) - schema: terra_pinyin # 地球拼音
如果想删除不经常使用的输入方案,可以在新建的 default.custom.yaml 中重写该配置。
patch:
schema_list:
- schema: luna_pinyin
- schema: luna_pinyin_simp
- schema: terra_pinyin
修改鼠须管外观(配色/横排/字体)
鼠须管的外观配置文件是 squirrel.yaml(小狼毫的外观配置文件是 weasel.yaml)。所以我们需要在用户配置目录下新建一个 squirrel.custom.yaml 文件:
patch:
# 修改程序外观
style:
color_scheme: solarized_dark # 选择配色主题(squirrel.yaml 源文件中预定义了多种主题)
font_face: Hei # 候选词字体(可以使用 macOS 自带的“字体册.app”检索)
font_point: 18 # 候选词大小
label_font_face: Bradley Hand # 候选词编号字体
label_font_size: 18 # 候选词编号大小
horizontal: true # 候选词是否横排
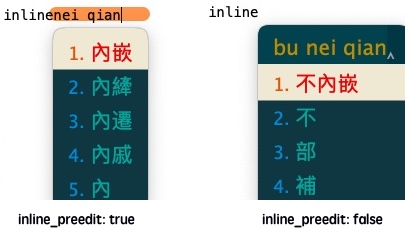
inline_preedit: false # true 将待转字母嵌入显示在目标程序窗口,false 将待转字母显示在输入法窗口
在 squirrel.yaml 文件中预定义了多种配色主题,我们可以通过 style/color_scheme 来选择一个主题,然后再设定其它 style 配置。
注意,(我不知道这算不算 bug)如果使用的主题中定义了某个属性,那么使用 style/<属性> 是无法覆盖主题中的同名属性的。必须使用如下方式:
patch: style/color_scheme: apathy # style/horizontal: false # 这无法覆盖预定义主题 apathy 中的配置 preset_color_schemes/apathy/horizontal: false # 这条才能覆盖预定义主题 apathy 中的配置
style/inline_preedit 的作用如下图所示:
消灭方框问号(生僻字)
Rime 预设的字典包含了许多系统无法显示的生僻字,由于 macOS 系统本身的字体不包含这些生僻字,所以会显示成下图所示的结果。

方案一
解决方法就是给系统安装更为全面的字体文件,比如「花园明朝字体」。安装好字体文件后,理论上无需修改配置,系统会自动为这些生僻字找到可用的字体。

方案二
另一种解决方案是可以使用 Lua 脚本自定义一个过滤器,从候选词列表中过滤掉生僻字。参考下面的「[Lua 扩展脚本]」章节。
一种解决方案是从 Rime 底层的 OpenCC 中删除那些生僻字,参考:https://github.com/funway/rime-rare-word。(我测试了下,他删除还不够彻底,还是残留不少原生字体无法识别的生僻字。)
网上还有一种使用原生过滤器(cjk_minifier、charset_filter)过滤生僻字的方法,不过看 Rime 在 github 上的 issue,新版本中好像已经不支持了。只能自己写 Lua 脚本。
或者更彻底的方法,就是使用从零开始自定义的词典文件,不导入 Rime 自带的词典。
在特定程序里默认开启英文输入
直接看官方文档吧:https://github.com/rime/home/wiki/CustomizationGuide#在特定程序裏關閉中文輸入
初识输入方案
一套输入方案必须包含「方案定义」文件和「词典」文件。
方案定义文件(.schema.yaml)
方案定义文件,以<schema_id>.schema.yaml格式来命名。我们来看一下预设的 luna_pinyin.schema.yaml 文件,这是 Rime 自带的朙月输入方案的方案文件。
文件的开头是这样的:
schema:
schema_id: luna_pinyin
name: 朙月拼音
version: '0.26'
author:
- 佛振 <chen.sst@gmail.com>
description: |
Rime 預設的拼音輸入方案。
schema/schema_id 是 Rime 中代表该输入方案的唯一标识。
schema/name 是该输入方案的名字,也是其呈现在 Rime 方案菜单中名字。
schema/version 是该方案的版本号
schema/author 是作者列表,schema/description 是对该输入方案的一段描述。
引擎与组件
然后是关于 engine 的配置。参考官方文档:輸入法引擎與功能組件 以及 https://jiz4oh.com/2020/10/how-to-use-rime/#engine
Rime 的核心原理是通过 enagine 下的 4 大组件对用户输入进行处理,4 大组件分别是:
ProcessorsSegmentorsTranslatorsFilters整个流程为:
Processors下的各个processor对用户的输入(即按下键盘的哪一个键)依次进行处理,将按键按照预设的规则对按键进行响应
- 不处理:Rime 不对该按键做任何响应,使用系统默认操作
- 特殊操作:比如
Enter上屏,切换输入方案、组合键等- 输入候选:该按键是需要转换为文字的按键,比如
123abc,将该按键字符存入【输入码】上下文- 当【输入码】上下文改变时,
Segmentors下的segmentor会将当前输入码根据格式分段,各自打上标签。比如【朙月拼音】中,输入码2012nian,划分为三个编码段:2012(贴number标签)、nian(贴abc标签)、(贴punct标签)。- 顾名思义,
Translators完成由编码到文字的翻译。但有几个要点:
- 翻译的对象是划分好的一个代码段。
- 某个
translator组件往往只翻译具有特定标签的代码段。- 翻译的结果可能有多条,每条结果成为一个展现给用户的候选项。
- 代码段可由几种
translator分别翻译、翻译结果按一定规则合并成一列候选。- 候选项所对应的编码未必是整个代码段。用拼音敲一个词组时,词组后面继续列出单字候选,即是此例。
- 翻译完成后,由
Filters对所有翻译结果进行处理,比如去重。Copied from https://jiz4oh.com/2020/10/how-to-use-rime/#engine
词典文件(.dict.yaml)
Rime 的词典文件命名格式为 <词典名>.dict.yaml。该文件中,只有开头部分的基本信息是 YAML 格式的。以朙月拼音的词典文件为例,其文件名是 luna_pinyin.dict.yaml。
# 注意這裏以 --- ... 分別標記出 YAML 文檔的起始與結束位置 # 在 ... 標記之後的部份就不會作 YAML 文檔來解讀 --- name: luna_pinyin version: "0.9" sort: by_weight use_preset_vocabulary: true ...
name: 词典名。可以与输入方案标识(schema_id)一样,也可以不一样。
version: 词典版本。
sort: 词条的排序方式,by_weight 表示按权重高低排序,original 表示按码表中出现顺序排序。注意,这个只是定义了候选词的默认顺序,在用户使用后,排序优先级最高的是用户的选择频率。
use_preset_covabulary: 表示是否导入预设的「八股文」词汇表(该词汇表文件为共享配置目录下的 essay.txt)。如果想要更精简的词典,你完全可以选择不导入该词汇表。
在这几个基本信息之后,就是一份“码表”。码表就是词条(包括单字与词组)与编码的对应关系,对于拼音输入法而言,其码表就是每个汉字和词组对应的拼音。
# 单字 你 ni 我 wo 的 de 99% 的 di 1% 地 de 10% # 表示使用习惯上,「地」字发 de 音占10%的概率 地 di 90% # 表示使用习惯上,「地」字发 di 音占90%的概率 # 词组 你我 # 会自动编码为「ni wo」 我的 # 会自动编码为「wo de」,但不会编码为「wo di」 好好地 # 会自动编码为「hao hao di」和「hao hao de」 天地 tian di 目的地 mu di di 周一 workday # 默认权重为1 周二 workday 5 # 如果使用了 by_weight 排序,那么输入 workday 候选词顺序应该是“周二 周三 周一” 周三 workday 3 # 这三条 workday 只是用作例子,最好不要将英文编码放在拼音系的字典中,因为这可能会影响对音节的切分
码表的每一行就是一条「词条 编码 (权重)」对应关系。其中第三个权重字段是可选的。
需要注意的是,字段之间的那个空白,必须是一个「Tab」制表符而不是空格符!(小心你的编辑器自动把制表符转换成空格符)
另外要注意的是,对于词组的编码,应该使用它们的完整拼音,并且每个字的拼音(音节)之间用空格隔开。这有利于拼音输入方案的 engine/segmentors 对音节进行切分。不应该使用拼音简写或者英文单词,这可能会干扰音节切分。这点会在后续的「[扩充字典]()」章节进行更详细的说明。
如下图所示,灰色横杆代表制表符,灰色圆点代表空格:
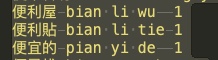
对于第三个字段。
- 如果是非负整数,则表示该词条相对于该编码的权重,当一个编码候选有多个词条时候,by_weight 排序方式将会使用该权重由高到低排序。
- 如果一个百分数(通常出现在单字后面),则表示该编码相对于该单字(多音字)的使用频率。这个频率值会用在词组的自动编码上。
如果词组满足以下两个条件,则可以省略编码字段,在编译过程中 Rime 会为其自动编码。
- 词组中的每个单字均有编码定义
- 词组中不包含多音字;或者多音字在词组中的读音,在单字的发音使用频率上超过5%。
比如说上面的例子中,由于「好好地」没有显示定义编码,所以编译时会自动编码为「hao hao de」与「hao hao di」两种。而对于「我的」这个词,虽然「的」是多音字,但由于发「di」音的频率只占了1%,所以在为「我的」自动编码的时候,只会编码成「wo de」。
编译输入方案
将写好的输入方案文件和词典文件“重新部署”到 Rime 的过程,就是一次编译。
为了查询效率,输入法在实际工作的时候,并不加载文本格式的词典文件。而是加载由词典文件编译生成的「.bin」文件。
共享目录下的 build 里放着程序发布时预编译好的「.bin」文件,用户目录下的 build 里放着用户点击“重新部署”后生成的「.bin」文件。
编译输入方案时候生成的二进制文件包括:
- 「Rime 棱镜」
<方案标识>.prism.bin - 「Rime 固态词典」
<方案标识>.table.bin - 「Rime 反查词典」
<方案标识>.reverse.bin
.table.bin 直接来自于词典源文件 .dict.yaml。
.prism.bin 则是结合了词典源文件与方案定义中的拼写运算规则而生成的二进制文件。(我猜测啊,应该是根据词典源文件中定义的音节编码,根据拼写运算规则,生成原音节与可替换音节的对应关系。比如原音节「lue」+拼写运算规则”derive/^([nl])ve$/$1ue/“,生成对应关系「lve」→「lue」。这样当用户输入「lve」时,就可以根据该对应关系去找「lue」的字)
.reverse.bin 是反查词典的二进制文件。所谓反查,以朙月拼音为例,其默认使用五笔画进行反查,就是当你不知道怎么用拼音打一个字的时候,可以按![]() 键,然后输入该字的五笔画,候选词列表中就会显示「候选词 + 朙月拼音编码」。
键,然后输入该字的五笔画,候选词列表中就会显示「候选词 + 朙月拼音编码」。
编译输入方案时,Rime 程序会做以下几件事:
- 将用户的定制内容合并到原始输入方案定义中,在用户配置目录的
build目录下生成新的.schema.yaml文件; - 根据输入方案指定的字典文件,记录单字、词组的编码;
- 对词典文件中未提供编码的词组进行自动注音;
- 建立按编码检索词条(词组或单字)的索引,即 Rime 固态词典;
- 建立按词条检索编码的索引,即 Rime 反查词典;
- 根据音节表和方案定义中的拼写运算规则,建立 Rime 棱镜。
拼写运算
如果没有拼写运算的话,用户就必须严格按照词典文件中的定义,输入正确的编码才能得到对应的候选词。
拼写运算是通过预定义的几种“运算符”,结合正则表达式,(在编译生成 .prism.bin 文件时)将一种编码替换为另一种编码,从而实现智能纠错、模糊音等功能。
详细的规则可以参考:https://github.com/rime/home/wiki/SpellingAlgebra
我们拿“只是”这个词组做例子,它的编码应该是「zhishi」。
现在我们修改 luna_pinyin.custom.yaml 文件中写入如下配置:
patch:
speller/algebra:
# 对,这里为空。它会覆盖(清空)原来的拼写运算配置
重新部署后,可以测试得到。
对于这两个单字,我们输入「zi」是查不到“只”字,输入「si」也查询不到“是“字。必须输入「zh」或「zhi」才能查询到“只”字,说明现在不支持模糊音查询。
对于这个词组,我们输入「zhsh」也查不到“只是”这个词,必须完整的输入「zhishi」才行。说明现在不支持对词组的简拼切分。(作者对简拼的定义,我认为是指以声母来列出所有使用该声母的字)
然后我们再修改上述配置文件:
patch:
speller/algebra:
- abbrev/^([a-z]).+$/$1/
- abbrev/^([zcs]h).+$/$1/
这两行的意思,就是将原词典中所有 [a-z] 开头的、以及 [zcs]h 开头的拼音编码,都归为对应的 [a-z] 或者 [zcs]h。换句话说,就是可以通过声母来查询所有使用该声母的单字。(但是实际上,不需要这个拼写运算规则,Rime 也支持对单字的简拼写法。所以我认为这个规则实际是用在词组的多音节切分的时候)
重新部署之后,我们可以发现输入「zhsh」总算可以出现候选词了。

这两条规则其实在 luna_pinyin.schema.yaml 原文件中已经定义了。
现在再来修改一下拼写运算规则:
patch:
speller/algebra:
- derive/^([zcs])h/$1/
这一行规则表示(在生成棱镜文件时候)对原词典中所有 [zcs]h 编码开头的,都可以等效替换为对应的 [zcs]。所以我们在输入「zi」编码的时候,就可以检索到所有「zi」与「zhi」对应的字;而输入「zhi」编码仍只有「zhi」。
如果想要在输入「zhi」编码时也能列出「zi」的单字。就需要再加一条规则:derive/^([zcs])([^h])/$1h$2/。
这两条规则,就可以实现 [zcs] 与 [zcs]h 的模糊音查询了。
模糊音支持
根据上面的拼写运算,我们现在来正式地修改 luna_pinyin.custom.yaml 文件,让朙月拼音支持模糊音查询。(由于朙月拼音的原方案定义文件中已经定义了简拼以及自动纠错的拼写运算规则,所以我们这里就要用 /+ 将新增规则与原规则合并,而不是替换原规则。)
patch:
speller/algebra/+: # 这里用 /+ 表示追加,而不是替换原配置值
# 下面两行实现 z、zh, c、ch, s、sh 的模糊音
- derive/^([zcs])h/$1/
- derive/^([zcs])([^h])/$1h$2/
# 下面两行实现 n、l 模糊音
- derive/^n/l/
- derive/^l/n/
# 下面两行实现 an、ang, en、eng, in、ing 的模糊音
- derive/([aei])n$/$1ng/
- derive/([aei])ng$/$1n/
ps:其实用起来,好像太模糊音了反而不习惯。
拼写运算调试器
官方还提供了一个拼写运算调试器。
修改标点符号
macOS 系统自带的拼音输入法在敲下键盘上的 / 键时会直接输入该符号「/」。对于鼠须管的朙月输入法而言,其默认配置在敲下 / 键时,会显示多个标点符号候选:

我们可以共享配置目录下找到朙月输入法的方案配置文件 luna_pinyin.schema.yaml。
punctuator:
full_shape:
# ... 省略 ...
"/": ["/", "÷"]
half_shape:
"/": ["、", "、", "/", "/", "÷"]
这两个配置表示,
在全角模式下,敲 / 键将会提示全角符号「/」与除号「÷」。
在半角模式下,敲 / 键将会提示全角顿号「、」,半角顿号「、」,半角斜杠「/」,全角斜杠「/」和除号「÷」。
我们可以通过下图来对比一下全角半角符号宽度区别:
为了在敲下 / 键时直接输出顿号「、」,可以在用户配置目录下新建一个 luna_pinyin.custom.yaml 文件:
patch:
punctuator/full_shape:
"/" : "、"
punctuator/half_shape:
"/" : "、"
luna_pinyin.custom.yaml 文件里的这两行配置就会覆盖 luna_pinyin.schema.yaml 的原配置。
输入法状态切换
我们来看一下朙月拼音的方案定义文件 luna_pinyin.schema.yaml,其中有这么一段定义:
switches:
- name: ascii_mode
reset: 0
states: [ 中文, 西文 ]
- name: full_shape
states: [ 半角, 全角 ]
- name: simplification
states: [ 漢字, 汉字 ]
- name: ascii_punct
states: [ 。,, ., ]
switches 表示该输入方案可切换的状态。 Rime 会记住输入方案的状态,这样在切换输入法的时候就不会丢失这些状态值。
其中 name 是用来标识一种状态的变量名。该状态变量实际上是 Rime 全局共享的,就是说如果朙月拼音输入方案与地球拼音输入方案都使用同一个状态变量「simplification」来标识简/繁状态,那么当切换朙月拼音为简体输出状态后,再切换到地球拼音输入法,那么也会保持简体输出。
states是可切换状态展示给用户的状态信息。如下图所示:

reset 告诉 Rime 不记住该状态值,每次切换到该输入方案时候都要重置该值,可选值为「0或1」。
这些状态变量会由 engine/translators 或 engine/filters 来捕获,并根据状态变量的值修改候选词列表。比如个过滤器 simplifier 就默认监听「simplification」状态变量来修改候选词的简繁。
定义简体字输出
如果只是要从繁体切换到简体,只需要按下组合键 `Ctrl+“,从方案选单中选择「漢字→汉字」即可。
Rime 预设的词典使用的是繁体字,是因为繁体字比简体字囊括的字更多,做「繁→简」转换能保证更高的精度。
如果想让朙月拼音默认使用简体字输出,那么我们可以在配置文件中为它的「simplification」状态变量添加一个 reset 属性。修改我们的 luna_pinyin.custom.yaml 文件:
patch: "switches/@2/reset": 1 # 表示将 switches 列表中的第2个元素(即 simplification 变量)重置为1,亦即简体汉字。
重新部署后,每次切换到朙月拼音输入法,就会自动变成简体输出。
朙月拼音·简化字版本与原版区别
Rime 预设了一套输入方案「朙月拼音·简化字」。从名字就可以看出,它是从原版的「朙月拼音」派生出来的。我们来看一下它的方案定义文件 luna_pinyin_simp.schema.yaml:
# 表示引入原版配置文件 luna_pinyin.schema.yaml 的根节点(即所有配置)
__include: luna_pinyin.schema:/
schema:
schema_id: luna_pinyin_simp # schema_id 必须与原版不同
# ...省略...
switches:
# ...省略...
- name: zh_simp # 使用新的状态变量来表示简繁状态
reset: 1 # 默认重置为1,即简体汉字
states: [ 漢字, 汉字 ]
# ...省略...
translator:
prism: luna_pinyin_simp # 使用与原版不同的棱镜文件(词典文件与原版相同)
simplifier:
option_name: zh_simp # 给 simplifier 过滤器传递 zh_simp 状态变量,而不是默认的 simplication 状态变量
key_binder:
bindings/+:
- { when: always, accept: Control+Shift+4, toggle: zh_simp }
- { when: always, accept: Control+Shift+dollar, toggle: zh_simp }
__include 并不是 YAML 自带的语法,而是 Rime 自己扩展的(https://github.com/rime/home/wiki/Configuration#語法)。可以用来引入同一文件其他节点,也可以用来引入其他文件的节点。由于引入了原版的配置,所以对于在后续定义中没有出现的配置项,就自动继承原版配置。
词典文件继承自原版,但是使用自己的棱镜文件。(我也不理解这样做是为了什么,我对比了一下简体版与原版生成的两个棱镜文件,除了文件头有两个字节不一样,后续完全一样。)
修改了 switches 中的简繁状态变量。并且使用了新的变量名,为的是不影响其他使用 simplication 作为简繁状态变量名的输入方案。因为使用了新变量名,所以需要在后面的 simplifier 过滤器配置中传递新的简繁状态变量。
在 key_binder 中新增了两个快捷键,用来切换简繁状态。
然后就没有啦!其他配置全继承自原版朙月拼音。
扩充词典
首先,新建一个词典文件 luna_pinyin.extended.dict.yaml。当然你也可以叫别的名字,只要文件名与词典中定义的 name 字段一致即可。比如你也可以叫做 my_first.dict.yaml。
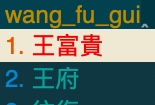
--- name: luna_pinyin.extended # 你也可以叫做 my_first(如果你的词典文件名是 my_first.dict.yaml) version: "2020.06.26" sort: by_weight use_preset_vocabulary: true # 在这里导入其他词典 import_tables: - luna_pinyin # 导入原版明月拼音的词典 ... # 下面是自定义的码表 # 注意事项: # 1、要使用繁体字(因为朙月拼音默认是使用繁体的,再由 OpenCC 转换为简体) # 2、「词条 编码 权重」三者要用制表符「Tab」键分隔 孖 ma 哈嗚 王富貴 # emoji 💅 mei jia 500 😄 kai xin 100 😂 ku xiao 100 # 颜文字 (๑‾ ꇴ ‾๑) ke ai 100 ⁽⁽٩(๑˃̶͈̀ ᴗ ˂̶͈́)۶⁾⁾ hui shou 100
其中 import_tables 字段是很有用的,我们可以通过它来导入其他的词典,比如网上下载到的词典文件(符合 Rime 格式)。
然后,还有很重要的一步,修改方案定义文件 luna_pinyin.custom.yaml。追加如下内容:
patch: # 使用自定义的扩展词典文件 translator/dictionary: luna_pinyin.extended
最后,重新部署之后,我们就可以使用上我们的扩展词典啦!
不要将英文单词用作拼音词典的编码
在 Rime 的 engine/segmentors 阶段,会对用户输入的编码做切分。对于拼音输入法来说,就是将用户输入的编码切分成可能的音节。如果在拼音系的词典文件中,混入了英文单词表示的编码,那么有可能会影响到对音节的切分。
我们举一个简单的例子,对于「mom」这个用户输入编码,由于默认的字典中不存在该编码,所以就会开始做音节切分,猜出可能对应的词组。

如果我们在扩充词典的时候,加入了「妈妈 mom」这一条对应关系。那么 Rime 就不会再对「mom」做切分,而是直接输出妈妈。

不要将简拼用作拼音词典的编码
同上面的英文单词「mom」一个道理,如果在字典文件中使用拼音简写来作为编码,也是会影响到对用户输入编码的切分。
我们以「msd」为例,对于默认的输入法,会显示如下候选词:

而但我们把「马上到 msd」这一行加入到词典文件中后,就会发现, Rime 不在对「msd」做切分了,而是直接输出“马上到”这个词组。
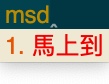
这并不是我们想要的结果。我们当然希望在输入「msd」时候,候选词列表中既要出现“马上到”,也要出现“魔术队”等等词组。
自定义短语
要想实现上面说的「mom」→ “妈妈”,「msd」→ “马上到”,并且不影响拼音的音节切分。实际上我们可以使用 Rime 的自定义短语功能。(官方文档实在太差了,提都没提这个功能,也难怪大家都抱怨 Rime 门槛高)
在用户配置目录下新建文件 custom_phrase.txt。
# 同詞典文件一樣,碼表各字段以製表符(Tab)分隔 # 順序爲:文字、編碼、權重(決定重碼的次序、可選) Rime rime 3 鼠鬚管 rime 2 媽媽 mom 馬上到 msd
custom_phrase.txt 这个文件名是默认写在朙月拼音的方案定义里的。如果想使用别的文件名,比如 my_phrase.txt,就需要修改方案定义 custom_phrase/user_dict: my_phrase。但自定义短语文件必须以 .txt 作为文件扩展名。
自定义短语不会被编译写入固态词典(.table.bin)或棱镜文件(.prism.bin),也不会写入实时更新的用户词典(.userdb)。而是在每次重新部署的时候直接读入内存。所以尽量不要在自定义短语文件中写入太多词条,怕影响载入效率(不过实际上写几万条是没问题的)。
自定义短语在候选词列表中的优先级最高,而且固定在列表首部(这点其实我觉得不是太好,习惯了 macOS 自带输入法的自定义短语,它们是可以调频的)。所以自定义短语有一个 trick 的用法,就是可以用来固定词序,比如你想在输入「z」时候“在”字一直排在第一位。
由于自定义短语是独立于词典的,所以尽量不要在自定义短语中定义拼音缩写。不然会出现这么一种情况,比如我们在自定义短语中定义了 「鼠须管 sxg」;然后使用时又通过输入「shuxuguan」选择了“鼠须管”三个字,这就使这个词组被写入用户词典。那么下次再输入简拼「sxg」的时候,就会同时出现两个“鼠须管”,第一个来自自定义短语,第二个来自用户词典。

进阶:Lua 扩展脚本
鼠须管从 0.12.0 版本开始就加入了 librime-lua 插件(小狼毫从版本 0.14.0 开始),用户可以通过 Lua 脚本编写自己的引擎组件(包括 processors、segmentors、translators、filters),来定制自己想要的功能。
Rime 默认加载 Lua 脚本路径应该为:用户配置目录/rime.lua。
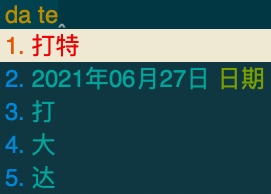
自动翻译日期
我们希望在输入「date」编码的时候,候选词列表中能自动显示当前的日期。这时候就要用到 Lua 脚本来实现了。
在用户配置目录下新建脚本文件 用户配置目录/rime.lua :
-- 两个短横杆代表 lua 的注释行
-- 翻译器:自动转换日期时间
function date_translator(input, seg)
if (input == "date") then
--- Candidate(type, start, end, text, comment)
yield(Candidate("date", seg.start, seg._end, os.date("%Y年%m月%d日"), "日期"))
end
end
然后还需要修改方案定义文件 luna_pinyin.custom.yaml,在翻译器字段中添加该 Lua 翻译器:
patch:
# 添加 lua 脚本的 translator
engine/translators/+:
- lua_translator@date_translator
重新部署之后,我们就可以在输入「date」时看到自动翻译出来的当天日期。
更多功能
请参考 https://github.com/hchunhui/librime-lua/blob/master/sample/rime.lua
比如在候选词列表使单字靠前排列的过滤器:single_char_filter
比如在候选词列表中自动反查地球拼音的过滤器:reverse_lookup_filter (需要保证用户配置目录下存在 build/terra_pinyin.reverse.bin 文件)
比如在候选词列表中过滤掉生僻字的过滤器:charset_filter
进阶:方案配置详解
参考:https://github.com/LEOYoon-Tsaw/Rime_collections/blob/master/Rime_description.md
每次重新部署之后,最终生成的方案定义文件(原文件与自定义配置合并之后) .schema.yaml 会放在用户配置目录的 build 文件夹下面。我们可以打开里面的方案定义文件一探究竟。
分词符
speller: delimiter: " '" # 这里有两个字符,分别是空格「 」与单引号「'」键
其中,第一个空格表示,在自动切分音节时,使用空格来作为回显,切分用户输入码。如果将它修改成下划线,你就会看到如下情况:
第二个单引号表示,用户在输入时,可以用「’」手工提示音节切分。比如输入「xi’an」,表示这是两个音节,「xi」和「an」,而不是一个音节「xian」。
输入码回显替换
或者叫做“上屏码”替换,就是将用户输入的字符替换成别的字符显示。比如我们敲下键盘「nv」,实际屏幕上显示的是「nü」。
明月拼音输入法默认的回显替换规则只有如下三条:
translator:
# ...省略其他...
preedit_format:
- "xform/([nl])v/$1ü/" # 将用户输入「nv」、「lv」显示为「nü」、「lü」
- "xform/([nl])ue/$1üe/" # 将用户输入「nue」、「lue」显示为「nüe」、「lüe」
- "xform/([jqxy])v/$1u/" # 将用户输入「jv」、「qv」、「xv」、「yv」显示为「ju」、「qu」、「xu」、「yu」
回显替换的规则有点像拼写运算,但两者作用不同。一个用来回显,一个用来查字。我们来看一下默认拼写运算规则的其中一条:
speller:
algebra:
# ...省略其他...
- "derive/^([jqxy])u/$1v/" # 表示将词典中所有「ju」编码的字同时归为「jv」编码,这样用户输入「jv」编码时就能查找到「ju」的字。
# ...省略其他...
特殊字符输入
使用明月拼音的时候,在输入「/」后再敲下某些字符,会显示出特殊字符来。比如敲「/sx」会列出很多数学符号,敲「/1」会列出跟1有关的符号,大小写字符等。这是如何做到的呢,我特意新建了一个输入方案来测试(通过删减 build/luna_pinyin.schema.yaml 得到):
# 这是用来做测试的输入法
schema:
schema_id: hello # 注意此 ID 與文件名裏 .schema.yaml 之前的部分相同
name: 测试方案 # 將在〔方案選單〕中顯示
version: "5" # 這是文字類型而非整數或小數,如 "1.2.3"
engine:
processors:
- recognizer # 与 segmentors/matcher 搭配,处理特定规则的输入码,如反查、网址、特殊符号等
- speller # 拼写处理器,将用户按键追加到输入码中
- punctuator # 处理符号按键
- selector # 处理候选词的选择(上下、翻页、序号选择)
- express_editor # 处理空格键(确认输入)、回车键(直接上屏)、退格键(删除输入)等
segmentors:
- matcher # 使用 recognizer 中定义的正则表达式来匹配输入码
- punct_segmentor
- fallback_segmentor # 无法被上述切分器识别的都落入到这里,并负责直接回显
translators:
- punct_translator # 标点符号翻译器
recognizer:
patterns:
punct: "^/([0-9]0?|[A-Za-z]+)$" # 匹配/号开头,以一个[0-9]数字加0次或者1次数字0为结尾;或者以1个或多个[字母]为结尾。
punctuator:
half_shape:
"/": ["、", "、", "/", "/", "÷"] # 这个必须保留
symbols:
"/0": ["〇", "零", "₀", "⁰", "⓪", "⓿", "0"]
"/1": ["一", "壹", "₁", "¹", "Ⅰ", "①"]
"/A": ["Ā", "Á", "Ǎ", "À"]
"/a": ["ā", "á", "ǎ", "à"]
"/sx": ["±", "÷", "×", "∈", "∏", "∑", "-", "+", "<", "≮", "=", "≠", ">", "≯", "∕", "√", "∝", "∞", "∟", "∠", "∥", "∧", "∨", "∩", "∪", "∫", "∮", "∴", "∵", "∷", "∽", "≈", "≌", "≒", "≡", "≤", "≥", "≦", "≧", "⊕", "⊙", "⊥", "⊿", "㏑", "㏒"]
从上面这个简化并且有效的输入方案可以看出来,首先「/1」输入码被 processors/recognizer 处理器捕获,并交给 segmentors/matcher 进行匹配,确认符合 recognizer/patterns/punct 规则,那么就会交给 translators/punct_translator 标点符号翻译器进行转换,它再根据自身的 punctuator/symbols 规则将输入码「/1」翻译成对应的特殊字符交给候选词列表(我们这里省略了 filters 组件)。
注意 punctuator/half_shape 中的「/」一对多候选必须保留。如果不定义这个多选项,而是让「/」键直接输出符号,那么就没有「/0」或者「/sx」这种输入码留着给 recognizer 去匹配了,因为一敲下「/」键它就被用掉了。
其他小技巧
删除错误上屏的词组
不小心输错了词组,那么再输入同样编码时,就会在候选词列表中出现错误词组,这会令有洁癖的人很难受。这时可以通过上下左右键将选词光标移动到要删除的词组上,再按下 Shift+Delete 或 Control+Delete (macOS 用户使用 Shift+Fn+Delete),即可删除该错误词组。
只能删除用户词典中的词组。对于码表中原有的词组,只会起到重置词频的作用。
修正错误的简繁转换
使用 Rime 输入「taitou」的时候,出现的备选词是【擡头】,而不是【抬头】。以及其他几乎所有跟【抬】有关的词语,都变成了【擡】。

究其原因,是因为:
① 根据现在的通识,【抬】字的简繁是不变的,都是【抬】。【擡】只是【抬】的异体字,而不是繁体。(参考:https://github.com/rime/home/issues/831)
② Rime 的 essay.txt 词汇表中,使用的是【擡】字进行组词。作者当初认为【擡】是繁体,【抬】是简体。
③ Rime 在底层使用 OpenCC 进行简繁转换,而 OpenCC 并不认为【擡】是繁体字,所以并不会将【擡】转换成【抬】。
要修正这种异常,有四种方式:
① (不推荐)修改 Rime 的共享配置文件 essay.txt,将其中包含【擡】字的词语,都改成【抬】,然后重新部署 Rime。
② (不推荐)修改 Rime 的用户配置文件 luna_pinyin.extended.dict.yaml(如果你用的是朙月拼音的话),在其中添加由【抬】字组成的词语,然后重新部署。但这样会导致【抬头】与【擡头】同时存在。
③ (推荐)去 Rime 项目的 github 仓库下载最新的 essay.txt 文件,作者已经将其中用到【擡】的词语都改成了【抬】。覆盖到共享配置目录中,然后重新部署 Rime。(顺便可以把 luna_pinyin.dict.yaml 字典文件也更新一下。我安装的鼠须管 0.15.2 版本,已经是当前最新版本了,但它共享配置目录下的 essay.txt 以及 xx.dict.yaml 文件都不如 github 上的新 =。=#)
④ (凑合)修改 Rime 的共享配置。在共享配置目录下的 opencc/ 子目录中,添加一个 TSCharacters_custom.txt 文件,然后写入一行「擡 抬」,注意中间是 Tab 符不是空格。然后再修改 t2s.json 文件,在其中的「conversion_chain」中增加TSCharacters_custom.txt 文件,使得 OpenCC 在进行 繁简转换 的时候,将【擡】字转换成【抬】。但这样有个坏处就是,简体输入法中再也找不到【擡】这个异体字了。

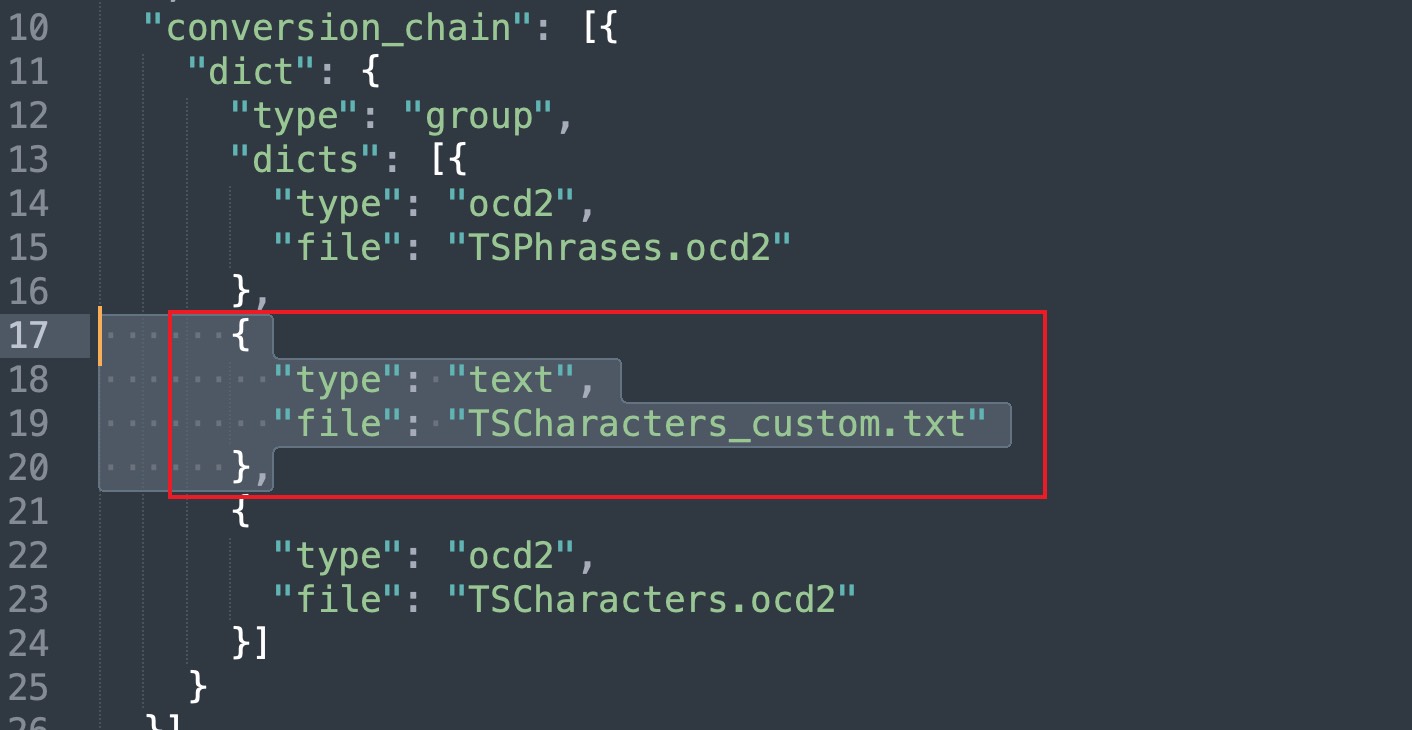
如果不想破坏共享配置目录下的 opencc/ 配置的话,可以在用户配置目录下面新建一个 opencc/ 目录,然后将要用到的 t2s.json 以及 ocd2 文件和自定义的 TSCharacters_custom.txt 文件放到用户配置目录/opencc/ 目录下。Rime 会优先加载用户配置目录下的 opencc 配置,如果没有的话,才会去找共享配置目录下的。
一些想法💡
1、对于 [自定义短语无法调频]() 的问题,是不是可以写一个 Lua 过滤器脚本,在候选词列表中先过滤掉来自自定义短语的词组,然后再将该词组写入动态用户词典。这样不就行了?
就是不知道底层有没有提供这种接口。好像有了 https://github.com/hchunhui/librime-lua/pull/80
2、mac 原生输入法的中英混输很好用啊。不是说中英一起。而是说我就在中文输入法的状态下,输入编码 volunt,它就会自动提示一个英文单词 volunteer。这个应该怎么做?

我现在用一种 trick 方法,就是将英文单词的编码,当作简拼,然后把它扩展成可识别的拼音。比如说:
Apple a po po le Google gou o o gou le Linux li nu xi macOS ma ce o si
这样,既不影响拼音的切分,又能利用简拼输入英文单词,还能支持调频。
唯一的缺点就是,在输入法的显示中,它会显示成编码切分的格式。请看下图,它是被切分成了四段:ma、c、o、s。对比下苹果原生的输入法如果输入「macOS」,其显示出来的编码是不会被切分的。

可不可以参考一下:https://github.com/BlindingDark/rime-easy-en (1、这个人的 patch include 写错了好像,直接copy到yaml内即可,不要用它的 include 示例。2、他有一个问题,虽然在明月拼音中引用了英文输入法,但是两者词频是割裂的。明月拼音会无视英文单词的词频,固定放在一个位置。)
3、 其实不管是自定义短语的问题、还是英文混输的问题,归根结底应该都是底层的切分器(segementors)和翻译器(translators)的问题。是不是可以用 Lua 脚本自己撸一个出来,能完美解决他们的编码与词频问题?
太强了,第一次看见写这么全的非官方
自定义短语有一个trick 的用法 这个用法 举个例子呀.
??【就是可以用来固定词序,比如你想在输入「z」时候“在”字一直排在第一位。】
谢谢!非常感谢!
请问下自造词放在哪里了呀?想把自己平时积累的自造词导出来不知道怎么弄?
你想要的是平时输入新词时候自动记录的那些是吧?
这个是以二进制形式保存在 input_method.userdb/ 目录下,没办法直接查看。
或者有一个折中的办法,可以查看它的同步目录下 sync/xxxxx/input_method.userdb.txt。这个文件可以看到你的输入历史,但可惜的是也不是以词典格式保存的。
如果你只是想把平时的输入历史同步到另一台电脑,拷贝这个 sync 目录过去即可。
如果你是想把这个 userdb 导出成 dict 文件,我不知道有没有这种工具。
想请问一下,如果想要连续输入多个#或者$或者%,该如何设置?目前的情况是连续按#会在#和№之间切换(这在写Markdown的时候特别不方便),连续按$会在各个货币符号之间切换。
修改 punctuator 配置 (修改标点符号配置)
感谢!
怎么重启和恢复鼠须管进程?我用rime和squirrel找过都没有。
1、Activity Monitor 里搜索 Squi
2、或者在命令行
ps -ef|grep Squi杀掉进程后,重新切换下输入法就自动起来了。
Squirrel 首字母大写。
可以用,非常感谢。
有史以来看过最好的第三方教程
完全同意。謝謝 哈呜 不吝分享使用和鑽研的心得及很多系統的細部內情!
感谢教程,解决了很多问题~另有个问题想请教:英文模式想要字母直接上屏(而不是还要按空格确认一下),应该如何设置呀
(・・ ) ? 英文模式本来就是直接上屏的呀不是吗?
还是说你指的是在中文模式下输入拼音时正好匹配到英文单词?如果是这点我就不知道了。
诶??我的英文模式下字母会出现在候选框里,要按一下空格确认才能上屏…我去研究一下是哪里出了问题,谢谢😂😂
请教:在五笔拼音混合输入方案下,如何配置输入时间日期?谢谢。
https://www.hawu.me/others/2666#%E8%87%AA%E5%8A%A8%E7%BF%BB%E8%AF%91%E6%97%A5%E6%9C%9F
这样不行吗? 那我也不知道了,已经好久没再折腾 Rime 的配置了。。
请问在雾凇拼音方案下,如何使用中文输入法打出自定义短语(邮箱格式)。不知道为什么我按照“example@email.com yx 1”这样的格式输入时无法正常显示这个短语。
1. 你是在 custom_phrase.txt 这个文件里面添加的吗? 确认你输入的 “example@email.com yx 1” 之间的分隔符是 tab 不是 空格?还有修改后重新部署了吗?
2. 是所有 custom_phrase.txt 文件里的自定义短语都不生效还是只有 yx 这个短语不生效? 如果所有自定义短语都不生效的话,有没有可能雾凇方案的 custom_phrase 配置指向的不是 custom_phrase.txt 文件? 这个可以在 wusong.schema.yaml 文件中找到 (我不知道文件名对不对,我没用雾凇方案,sorry)。
感谢大佬,后面又尝试了下,发现只有那一个词条是不生效的,无论修改拼音还是权重,但在这个词条之前和之后的词条却能实现。后面把这个词条删除重新输入了一遍,莫名其妙的又可以生效了。
非常感觉,对我的帮助很大。
感谢