, Programming
, Programming  , and Thinking
, and Thinking 
好像从python开始流行起,他就与爬虫扯上关系了。一提起python就想到爬虫程序,可能是因为python提供的库(模块)比较方便吧,不管是自带的urllib,还是各种第三方库。总结一下我所了解的关于python爬虫的知识,我觉得可以将这些库分为下面四大类:http协议库,文档解析库,模拟浏览器,爬虫框架。
1. urllib、urllib2、urllib3、requests
urllib、urllib2是python 2自带的http库,它们负责请求url链接并返回结果。urllib2并不完全是对urllib的升级,有时候得urllib跟urllib2一起用,比如当你想在POST请求中带上参数的话,就得用urllib.urlencode()来格式化参数,就是这么蛋疼。不过在python 3后,urllib跟urllib2就合并了。
自带的urllib、urllib2有很多局限,比如说链接不可重用(http请求头的connection值总是close)。
urllib3、requests都是针对urllib、urllib2改进的第三方库。requests的底层是用urllib3来实现的,并且比urllib3提供了更强大的接口。
so,可以说,现在最方便的http库应该就是requests了。
2. beautiful soup
beautiful soup是用来解析html、xml文档的第三方库,它支持多种解析引擎(包括原生的html引擎、lxml引擎、html5lib引擎)。
通常的工作流程是先使用urllib库请求某个url,然后将返回的html数据传递给beautiful soup进行解析。
通过urllib(requests)+beautiful soup结合可以很好地爬取静态网页的内容。但现在的web技术,Ajax跟node.js大行其道,很多网页内容是通过javascript动态生成的,简单地html爬虫对此根本就无能为力,除非你能破译出javascript动态加载的目标url,然后再访问该地址并解析数据。或者,可以考虑使用“模拟”浏览器来解析页面的dom模型,并进行操作。
3. ghost、selenium
ghost 是一个基于QtWebKit的无窗口浏览器。但文档超寒酸,而且实现的功能也少,与其琢磨它的源代码,还不如自己学习下PyQt或者PySide,然后直接调用QtWebKit来的简单粗暴。
selenium 是一个可支持多款本地浏览器的“驱动器”,它同时提供多种程序语言接口。我们可以通过【python + selenium webdriver】来驱动Firefox或者PhantomJS来访问网页、搜索dom元素并进行各种操作。特别的,对于通过Ajax来进行动态加载的网页内容,selenium简直就是人们的大救星。
关于selenium的基本用法我前两天也写过一篇文章《python的浏览器“驱动”库:selenium》
4. scrapy
scrapy是一款最负盛名的python爬虫框架,不过我个人还没用到过。而且据我所知,scrapy只能爬取静态页面内容,对于javascript动态生成的内容,可以尝试scrapy+ScrapyJS的结合。
关于scrapy可以参考如下两个文档:
http://doc.scrapy.org/en/1.0/topics/architecture.html
http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/item-pipeline.html
5. Examples
我们来用花瓣网首页(http://huaban.com)做几个例子
1. requests + beautiful soup
先简单地使用requests库来请求花瓣网的首页,并交给beautiful soup解析。
# -*- coding: utf-8 -*-
__author__ = 'funway'
import sys
import requests
from bs4 import BeautifulSoup
reload(sys)
sys.setdefaultencoding('utf-8')
def main():
#向http://huaban.com地址发出http请求
r = requests.get('http://huaban.com')
#打印请求结果
print '状态码: %s\n'%r.status_code
print '请求头: %s\n'%r.request.headers
print '响应头: %s\n'%r.headers
#print '响应内容: %s\n'%r.text
#将响应内容传递给beautiful soup,并使用lxml解析引擎来解析该文本
soup = BeautifulSoup(r.text, 'lxml')
#打印解析出来的html <title>标签
print soup.title
if __name__ == '__main__':
main()
从输出的结果,可以发现,requests库请求返回的响应内容,跟使用右键“查看页面源代码”是一样的。这对于大部分简单地页面来说足够了。但对于页面中那些通过javascript动态加载内容,requests这种单纯的http库就无能为力了。以花瓣网首页搜索框下面的热门搜索为例: 这一行在dom模型中是这样的,包围在一个class=”hot-words”的div标签里面:
这一行在dom模型中是这样的,包围在一个class=”hot-words”的div标签里面: 如果在首页源代码中存在这个标签,那么我们可以直接通过beautiful soup的find函数找到该元素:
如果在首页源代码中存在这个标签,那么我们可以直接通过beautiful soup的find函数找到该元素:
soup.find('div', class_='hot-words')
但实际上,在花瓣首页的源代码中,根本没有这个div标签,而是将热门搜索的数据存放在如下javascript变量中,然后通过javascript来动态生成dom元素。

对于这种javascript动态生成的情况,我们有两种方法可以解决:
- 阅读页面源代码,找出其中动态加载内容的规律,破译出他们的url,然后再对该url发起请求。就像上面的花瓣热门搜索这样,我们已经发现他的热门搜索是放在app.page[“hot-words”]这一行代码中,包括热门搜索的关键字以及url。
- 使用“模拟浏览器”来加载页面,然后直接操作其dom元素。
2.selenium
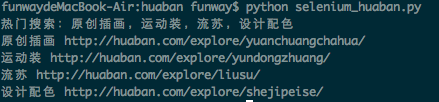
现在来测试一下使用python+selenium来定位花瓣首页的“热门搜索”:
# PhantomJS - huaban
from selenium import webdriver
from selenium.webdriver.remote.command import Command
driver = webdriver.Firefox()
# driver.set_window_size(800,600)
driver.get('http://huaban.com')
element = driver.find_element_by_class_name('hot-words')
print element.text
hotwords = element.find_elements_by_tag_name('a')
for hotword in hotwords:
print hotword.text, hotword.get_attribute('href')
driver.quit()
输出结果如下: