What is the XFA form?
First, you need to know there are two types of PDF forms, XFA, and Acroform. (See the doc)
Acroform is an old interactive form technology by Adobe, but it is more commonly used and supported by many third-party software.
XFA is newer than Acroform, it’s more complicated and not supported very well by other third-party software.
XFA has been deprecated in PDF 2.0, but unfortunately, it is still a common format for many gov documents today. If you want to handle it programmatically, you have to face a situation with insufficient library and information support.
A PDF form could contain either XFA or Acroform structure, or both (that’s the most horrible 😡).
Structure of the XFA form
The XFA structure in pdf was saved as an XML Data Package (XDP). It looks like the following picture.
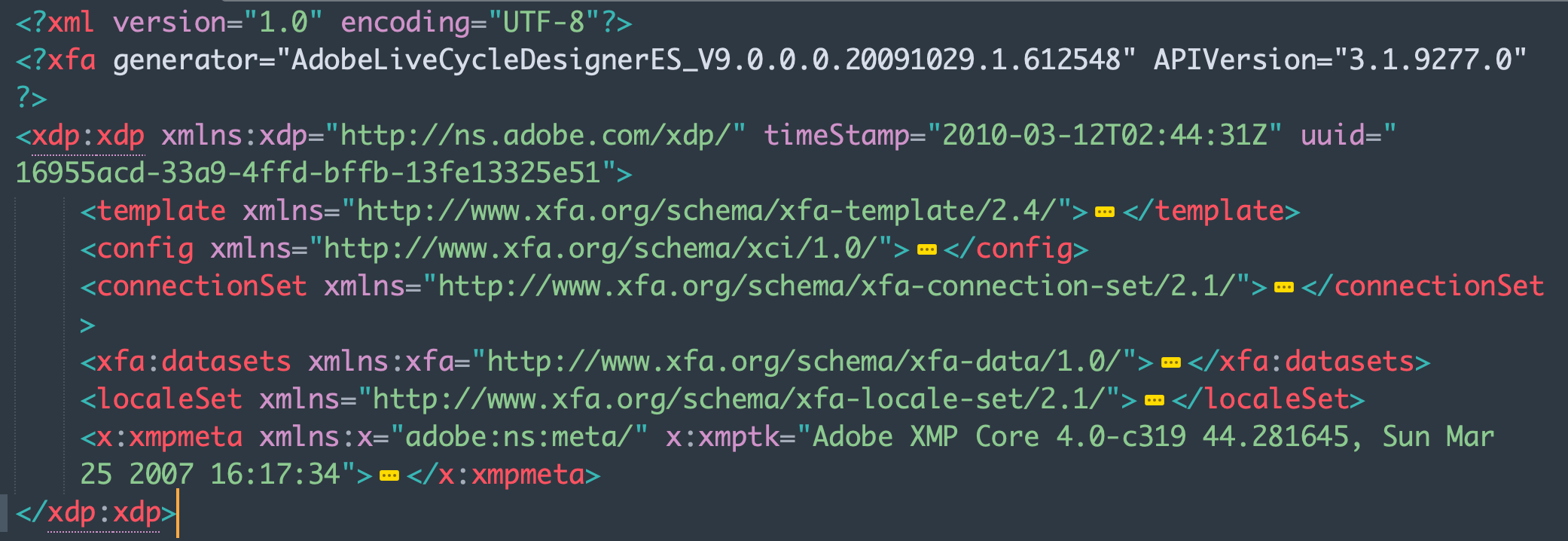
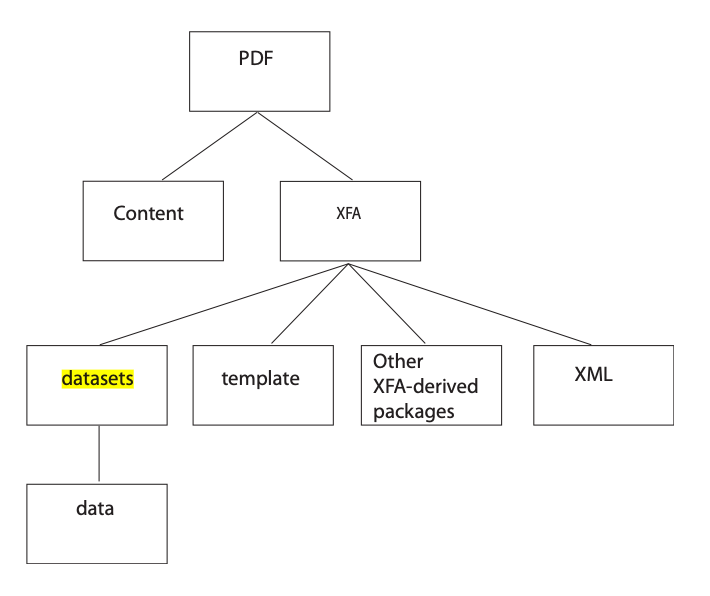
The root node in the XML is <xdp:xdp>, it has some child nodes. The two most important of which are <template> and <xfa:datasets>.
<template>describes the appearance and interactive characteristics of an interactive form. It was designed from the ground up to be an XML-based template language.<xfa:datasets>(with its subnode<xfa:data>) contains the real data of the form.
The following image illustrates the structure of an XFA PDF.
Extracting XML data by Java with iText7
As far as I know, the best library that could manipulate XFA form easily in Java is iText. So I wrote an example code with iText7 to demonstrate how to extract form data from PDF.
import com.itextpdf.forms.PdfAcroForm;
import com.itextpdf.forms.fields.PdfFormField;
import com.itextpdf.forms.xfa.XfaForm;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.PdfReader;
import java.io.FileWriter;
import java.io.FileOutputStream;
import java.util.Map;
import javax.xml.transform.OutputKeys;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class ExtractorUsingItext {
public static String getGreeting() {
// return this.getClass().getName();
return ExtractorUsingItext.class.getName();
}
/**
* Extract Acroform fields from a PDF file, and save as a text file.
* @param src the path of source PDF file
* @param dest the output file
*/
public static void extractAcroformFields(String src, String dest) {
try (PdfReader reader = new PdfReader(src)) {
reader.setUnethicalReading(true);
PdfDocument pdfDoc = new PdfDocument(reader);
PdfAcroForm acroForm = PdfAcroForm.getAcroForm(pdfDoc, false);
if (acroForm != null) {
Map<String, PdfFormField> fields = acroForm.getFormFields();
if (fields.size() == 0) {
System.out.println("iText: The pdf document does not contain an Acroform field.");
return ;
}
FileWriter writer = new FileWriter(dest);
for (Map.Entry<String, PdfFormField> entry : fields.entrySet()) {
String fieldName = entry.getKey();
PdfFormField field = entry.getValue();
String fieldValue = field.getValueAsString();
writer.write("Field Name: " + fieldName + "\n");
writer.write("Field Value: " + fieldValue + "\n");
writer.write("---------------------------\n");
}
writer.close();
} else {
System.out.println("iText: The pdf document does not contain an Acroform.");
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* Extract all level-1 subnodes from XFA structure in a XFA PDF.
* @param src src the path of source PDF file
* @param destPath the dest folder to save subnodes' XML data
*/
public static void extractXfa(String src, String destPath) {
try (PdfReader reader = new PdfReader(src)) {
reader.setUnethicalReading(true);
PdfDocument pdfDoc = new PdfDocument(reader);
PdfAcroForm acroForm = PdfAcroForm.getAcroForm(pdfDoc, false);
if (acroForm != null && acroForm.getXfaForm() != null) {
XfaForm xfa = acroForm.getXfaForm();
Document domDoc = xfa.getDomDocument();
Element rootElement = domDoc.getDocumentElement();
if (rootElement != null) {
System.out.println("Root Element Name: " + rootElement.getNodeName());
// System.out.println("Root Element Value: " + rootElement.getTextContent());
if (rootElement.hasAttributes()) {
System.out.println("Root Element Attr:");
for (int i = 0; i < rootElement.getAttributes().getLength(); i++) {
System.out.println(" " + rootElement.getAttributes().item(i).getNodeName() + ": "
+ rootElement.getAttributes().item(i).getNodeValue());
}
}
// get all first level children
NodeList childNodes = rootElement.getChildNodes();
for (int i = 0; i < childNodes.getLength(); i++) {
Node childNode = childNodes.item(i);
if (childNode.getNodeType() == Node.ELEMENT_NODE) {
Element childElement = (Element) childNode;
String childName = childElement.getNodeName();
System.out.println("Child Node: " + childName);
childName = childName.replace(':', '_');
String output = destPath + "/" + childName + ".xml";
try (FileOutputStream fileOutputStream = new FileOutputStream(output)) {
// byte[] bytes = childElement.getTextContent().getBytes();
// fileOutputStream.write(bytes);
Transformer transformer = TransformerFactory.newInstance().newTransformer();
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
transformer.transform(new DOMSource(childElement), new StreamResult(fileOutputStream));
}
}
}
}
} else {
System.out.println("iText: The pdf document does not contain an XFA form.");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
iText is open-source under the AGPLv3 license, which means it’s not suitable for commercial usage if you don’t buy their authorization. After that, I found a more commercially friendly library, OpenPDF, which is derived from iText4.
I wrote a similar example with the OpenPDF library, you can find it on my GitHub.
Extracting XML by Python with pikepdf
There is a repo in GitHub that uses Python with pikepdf library to extract XML data from the XFA form. However, I haven’t found a Python library that makes it easy to write XFA form. So, I have to use Java with iText and OpenPDF in my new project to manipulate XFA forms.
Fill out the XFA form programmatically
use iText.Forms.Xfa.XfaForm.FillXfaForm.fillXfaForm(new FileInputStream(xml));.
But Remember! Do not keep the <xfa:datasets> and <xfa:data> tags in the XML file if you fillXfaForm from an XML file, just start with the next level behind <xfa:datasets> <xfa:data>.

Or you can use the fillXfaForm(Node node) method, in which the node must be the <xfa:data> node.
import com.itextpdf.forms.PdfAcroForm;
import com.itextpdf.forms.xfa.XfaForm;
import com.itextpdf.kernel.pdf.PdfDocument;
import com.itextpdf.kernel.pdf.StampingProperties;
import com.itextpdf.kernel.pdf.PdfReader;
import com.itextpdf.kernel.pdf.PdfWriter;
import java.io.InputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.xpath.XPath;
import javax.xml.xpath.XPathConstants;
import javax.xml.xpath.XPathFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Node;
public class FillerUsingItext {
public static void fillXfaData(String src, String dest, InputStream is) throws Exception {
System.out.println("Fillout by Itext");
System.out.println("src: " + src);
System.out.println("dest: " + dest);
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(is);
Node rootNode = document.getDocumentElement();
System.out.println("Root Node: <" + rootNode.getNodeName() + ">");
Node dataNode = document.getElementsByTagName("xfa:data").item(0);
System.out.println("Data Node: <" + dataNode.getNodeName() + ">");
// Edit the Dom elements
// XPath xPath = XPathFactory.newInstance().newXPath();
// String expression = "/datasets/data/IMM_5645/page1/Subform1/Student";
// Node node = (Node) xPath.compile(expression).evaluate(document, XPathConstants.NODE);
// if (node != null) {
// System.out.println("Found node: " + node.getNodeName() + " = " + node.getTextContent());
// node.setTextContent("1");
// } else {
// System.out.println("Cannot found node: " + expression);
// }
fillXfaData(src, dest, dataNode);
} catch (Exception e) {
throw e;
}
}
public static void fillXfaData(String src, String dest, Node node) throws Exception {
System.out.println("Node name: " + node.getNodeName());
if (node.getNodeName() != "xfa:data") {
throw new IllegalArgumentException("Node is not <xfa:data>.");
}
// Get first ELEMENT_NODE (exclude TEXT_NODE, COMMENT_NODE ...)
Node dataNode = getFirstElementNode(node);
if (dataNode == null) {
throw new Exception("No valid element found under the given node.");
}
try (PdfReader reader = new PdfReader(src);
PdfWriter writer = new PdfWriter(dest)) {
reader.setUnethicalReading(true);
StampingProperties sp = new StampingProperties();
sp.useAppendMode();
sp.preserveEncryption();
// using StampingProperties to keep old pdf's encryption and other attribute.
PdfDocument pdfDoc = new PdfDocument(reader, writer, sp);
PdfAcroForm acroForm = PdfAcroForm.getAcroForm(pdfDoc, true);
XfaForm xfa = acroForm.getXfaForm();
xfa.fillXfaForm(dataNode);
xfa.write(pdfDoc);
pdfDoc.close();
} catch (Exception e) {
throw e;
}
}
private static Node getFirstElementNode(Node node) {
NodeList nodeList = node.getChildNodes();
for(int i=0; i<nodeList.getLength(); i++) {
Node chilNode = nodeList.item(i);
if (chilNode.getNodeType() == Node.ELEMENT_NODE) {
return chilNode;
}
}
return null;
}
}
Repo of example code
I wrote a Gradle project as an example: https://github.com/funway/pdfform. You could check the source code from “app/src/main/java/pdfform“.